
Using machine learning techniques as a data analyst can help you get new insights and improve data-driven decision-making. Scikit-Learn is an advanced and user-friendly Python-based framework that provides a variety of machine-learning techniques. In this tutorial, we’ll walk you through the fundamentals of utilising Scikit-Learn, using real examples to get you started on your path to being a skilled data analyst.
Installing Scikit-Learn
Before we dive into the tutorial, make sure you have Scikit-Learn installed. You can install it using pip: “pip install scikit-learn” in your command line. Once Scikit-Learn is installed, we can begin importing it into our Python program and explore the various tools and functionalities it offers for data analysis and machine learning. With Scikit-Learn, we can easily preprocess our data, split it into training and testing sets, and apply a wide range of algorithms such as linear regression, decision trees, and support vector machines for predictive modelling.
Importing the Necessary Libraries
To begin, let’s import Scikit-Learn and other essential libraries. Some of the essential libraries include NumPy for mathematical functions, Pandas for data manipulation, and Matplotlib for data visualization. Importing these libraries will provide a solid foundation for the data analysis and machine learning tasks ahead. Furthermore, importing Scikit-Learn, a popular machine-learning library, will allow us to utilize its extensive range of algorithms and techniques for predictive modelling. Overall, starting with these imports will set us up for success and streamline our workflow throughout the project.
Loading and Preparing the Data
For this tutorial, let’s consider a simple linear regression example.
A linear regression model is a fundamental statistical tool used in machine learning and statistics. It’s employed to understand the relationship between a dependent variable (often denoted as y) and one or more independent variables (often denoted as x). In simple linear regression, like the one being used in this tutorial, we have only one independent variable.
The model assumes that the relationship between the variables can be well approximated by a straight line. It’s used for tasks such as predicting future values of the dependent variable based on new values of the independent variable or understanding the strength and direction of the relationship between the variables.
In this specific tutorial, we’re using a simple linear regression example to demonstrate the process of creating and training a basic machine learning model. It’s a great starting point for those new to machine learning because it’s relatively easy to understand and implement. Additionally, it serves as a foundation for more complex models and techniques in the field.
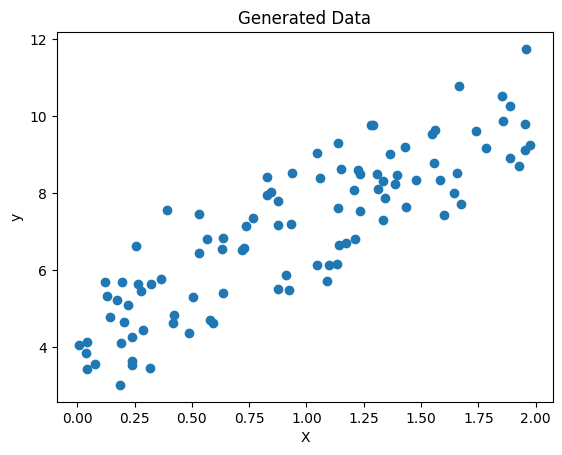
We’ll generate some random data to work with. We’ll use the Python programming language and the NumPy library to generate the data. We’ll define the number of data points we want to generate and the range of values for the independent variable. Finally, we’ll use the NumPy random module to generate random values for the independent variable and a linear equation to generate the corresponding dependent variable values.

Splitting the Data
Next, we’ll split our data into training and testing sets. This allows us to evaluate the performance of our model on data it hasn’t seen before. By dividing the data into training and testing sets, we can ensure that our model is not biased in favour of the training data. The training set will be used to train the model and adjust its parameters, while the testing set will be used to assess how well the model generalizes to unseen data. This evaluation helps us gauge the model’s ability to make accurate predictions in real-world scenarios.

Choosing and Training a Model
In this example, we’ll use a simple linear regression model. Scikit-Learn makes it easy to instantiate, train, and use various machine learning models. One of the advantages of using Scikit-Learn is that it provides a consistent API for different machine-learning models. The process of training a linear regression model involves feeding the model with a set of input features and their corresponding target values. Once trained, the model can be used to make predictions on new data by simply providing the input features.

Making Predictions
Once the model is trained, we can use it to make predictions on new data. These predictions can help us gain insights, make informed decisions, and improve our understanding of the underlying patterns in the data. By applying the trained model to new data, we can anticipate future outcomes, detect anomalies, or classify unknown instances. This predictive power allows us to leverage the knowledge gained from the training process to make accurate and timely predictions in real-world scenarios.

Evaluating the Model
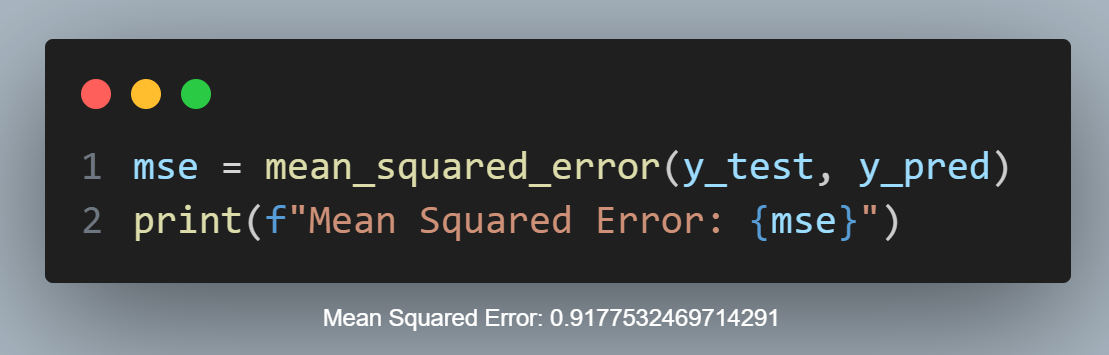
To assess the performance of our model, we’ll use the mean squared error (MSE) metric. This metric allows us to determine the extent to which our model’s predictions deviate from the ground truth values. By calculating the average of the squared differences, we can obtain a comprehensive understanding of the accuracy of our model’s predictions. Comparing the MSE values of different models or techniques will enable us to identify the most reliable and accurate one. The lower the MSE value, the more precise and consistent our model is in its predictions.
Conclusion
Congratulations! You have just finished a hands-on lesson on how to get started with Scikit-Learn. You’ve learned how to import data, split it for training and testing, choose and train a machine learning model, and evaluate its performance.
Scikit-Learn offers a diverse set of models and tools for a variety of machine-learning tasks. This collection will be an essential addition to your toolset as a data analyst. Continue to explore and experiment with various models to obtain a better grasp of their strengths and applications.
Remember that practice makes perfect, so keep working on projects and investigating new datasets.
Click here to read our post on A Guide to Choosing the Right Machine Learning Framework for Your ML Projects


