
Data cleaning is a critical step in the data analytics process. It involves identifying and correcting errors or inconsistencies in datasets to ensure accurate and reliable analysis. In this guide, we’ll explore a range of data-cleaning tools, including libraries, frameworks, and applications, to help you efficiently clean and prepare your data for analysis. Data cleaning is essential because it helps improve the quality of data and enhances the overall data analysis process. By identifying and fixing errors, such as missing values, outliers, or duplicates, analysts can avoid misleading or biased results. Utilizing various data cleaning tools can save time and effort and ensure that the data is in a consistent and usable format, enabling practical analysis and decision-making.
Libraries for Data Cleaning
- Pandas
Pandas is a widely used Python library for data manipulation and analysis. It provides powerful tools for cleaning, transforming, and preparing data. Some common data cleaning tasks with Pandas include handling missing values, removing duplicates, and performing data normalization. Additionally, Pandas offers functions for data exploration, such as filtering, sorting, and grouping data. It also supports various data formats, allowing users to import and export data from different sources. With its intuitive and flexible syntax, Pandas makes it easier for analysts and data scientists to analyze and visualize data, enabling them to derive meaningful insights and make data-driven decisions. Overall, Pandas is an essential tool in the data science toolkit, empowering users to efficiently work with and manipulate large datasets.

- NumPy
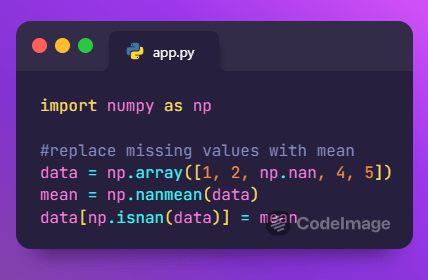
NumPy is a fundamental library for numerical computation in Python. It provides powerful tools for handling arrays and matrices. While not explicitly a data-cleaning library, NumPy is invaluable for tasks like replacing missing values with meaningful statistics or performing element-wise operations.
Additionally, NumPy offers efficient mathematical functions and algorithms that make it easier to manipulate and analyze data. Its ability to handle large datasets and perform computations quickly makes it a popular choice among data scientists and researchers. Furthermore, NumPy seamlessly integrates with other libraries such as Pandas and Matplotlib, enhancing its capabilities for data preprocessing and visualization.
Frameworks for Data Cleaning
- Apache Spark
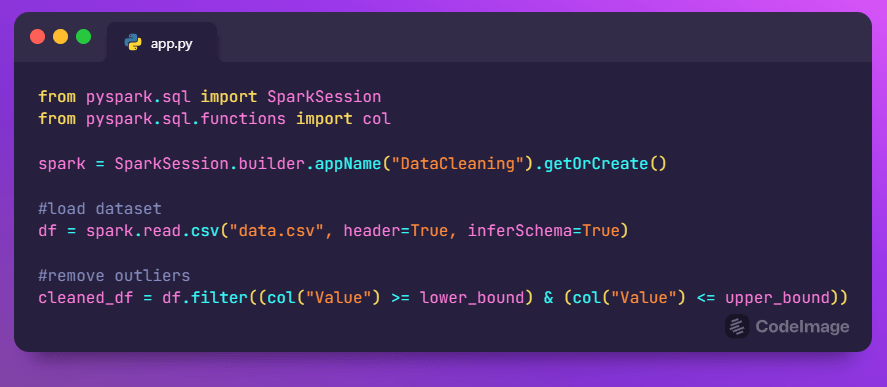
Apache Spark is a powerful distributed computing framework that includes modules for data cleaning and processing. It’s ideal for handling large-scale datasets and performing transformations in parallel.
With its ability to distribute data across a cluster of computers, Apache Spark can efficiently process massive amounts of data in a fraction of the time compared to traditional computing frameworks. Additionally, its built-in libraries for machine learning and graph processing make it a versatile tool for a wide range of data analysis tasks. Overall, Apache Spark empowers data scientists and engineers to extract valuable insights from big data with ease and efficiency.
Example: Removing Outliers
Applications for Data Cleaning
- OpenRefine
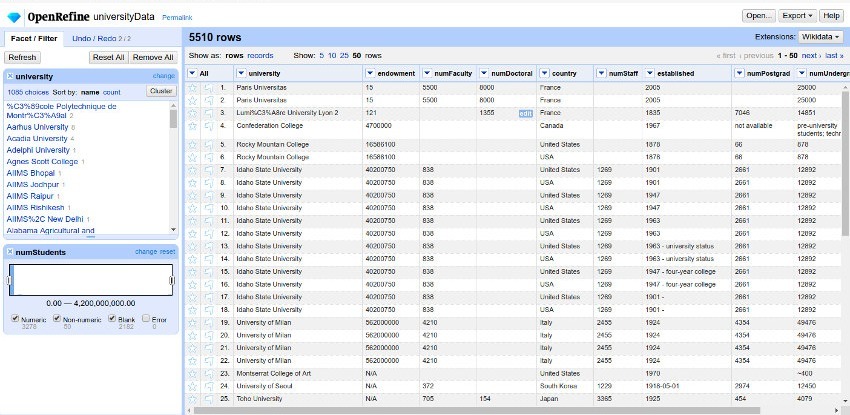
OpenRefine (formerly Google Refine) is a free, open-source tool for cleaning and transforming messy data. It provides a user-friendly interface for tasks like clustering similar records, reconciling data, and standardizing formats. OpenRefine is widely used by data scientists, researchers, and analysts to improve the quality and accuracy of their datasets. Its powerful capabilities allow users to identify and correct errors, remove duplicates, and merge data from multiple sources. By streamlining the data cleaning process, OpenRefine saves valuable time and effort, enabling users to focus on analyzing and extracting insights from their data.
- DataRobot
DataRobot is an automated machine learning platform that includes data cleaning as part of its feature set. It employs intelligent algorithms to automatically identify and clean problematic data, saving time and effort. This data-cleaning process involves identifying missing values, outliers, and inconsistencies in the dataset. DataRobot also provides options to handle these issues, such as imputing missing values or removing outliers. By streamlining the data cleaning process, DataRobot allows users to focus on more critical tasks like feature engineering and model selection. Overall, its automated approach enhances efficiency and accuracy in machine learning workflows.
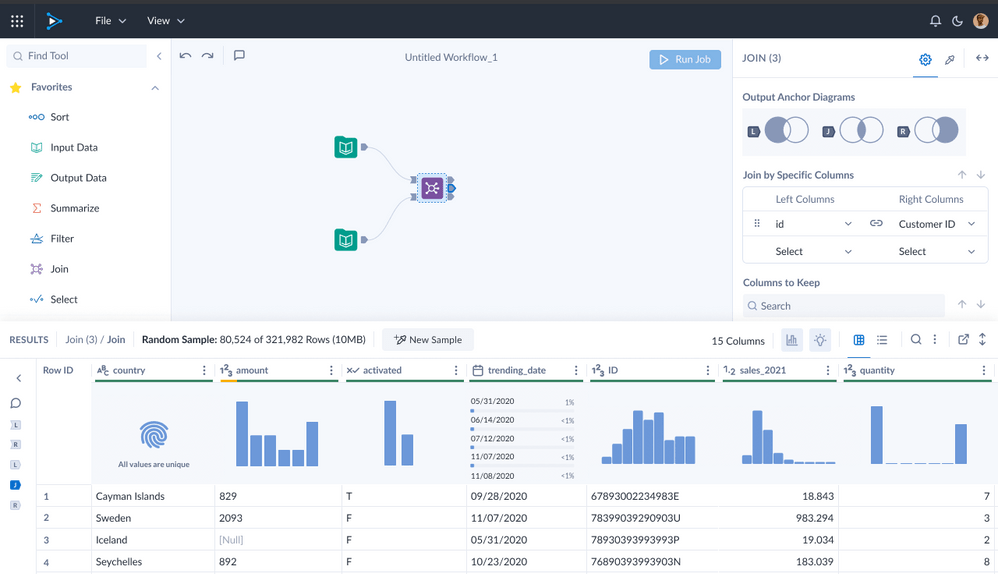
- Alteryx Designer Cloud
Alteryx Designer Cloud is a user-friendly data-cleaning platform that offers a visual interface for data wrangling. It allows users to explore, clean, and transform data without writing code, making it accessible to a broader audience.
Alteryx Designer Cloud’s visual interface simplifies the data cleaning process, allowing users to easily navigate and manipulate their data. With its intuitive drag-and-drop functionality, users can quickly identify and fix errors, remove duplicates, and standardize formats. This user-friendly approach enables data professionals and non-technical users alike to efficiently prepare their data for analysis or further processing.
Conclusion
Efficient data cleaning is essential for accurate and reliable data analysis. Whether you choose to work with libraries like Pandas and NumPy, powerful frameworks like Apache Spark, or user-friendly applications like Trifacta and OpenRefine, having the right tools at your disposal can significantly streamline the data-cleaning process.
Remember to choose tools that align with your specific needs, whether it’s working with large-scale datasets, automating the cleaning process, or providing a user-friendly interface for non-technical users. With the right tools, you’ll be well-equipped to tackle data-cleaning challenges in your analytics projects.
Want to know about the essential steps in cleaning data? Check out our post on Tidy Data.


