
Data is the lifeblood of any data-driven project. However, before we can extract meaningful insights, we must clean and preprocess our data. In this step-by-step guide, we’ll walk through essential data cleaning and preprocessing techniques using Python, providing practical examples and code snippets to make the process accessible and effective.
1. Handling Missing Values
Dealing with missing values is a critical aspect of data cleaning. To address missing values in data, several strategies can be employed. First, remove rows or columns with few missing values, which don’t significantly impact the dataset. Second, impute missing values with calculated estimates, like the mean or median, when they’re small and reasonably estimated. Third, use advanced techniques like multiple imputation or machine learning algorithms to predict and fill in missing values based on data patterns and relationships.

2. Removing Duplicates
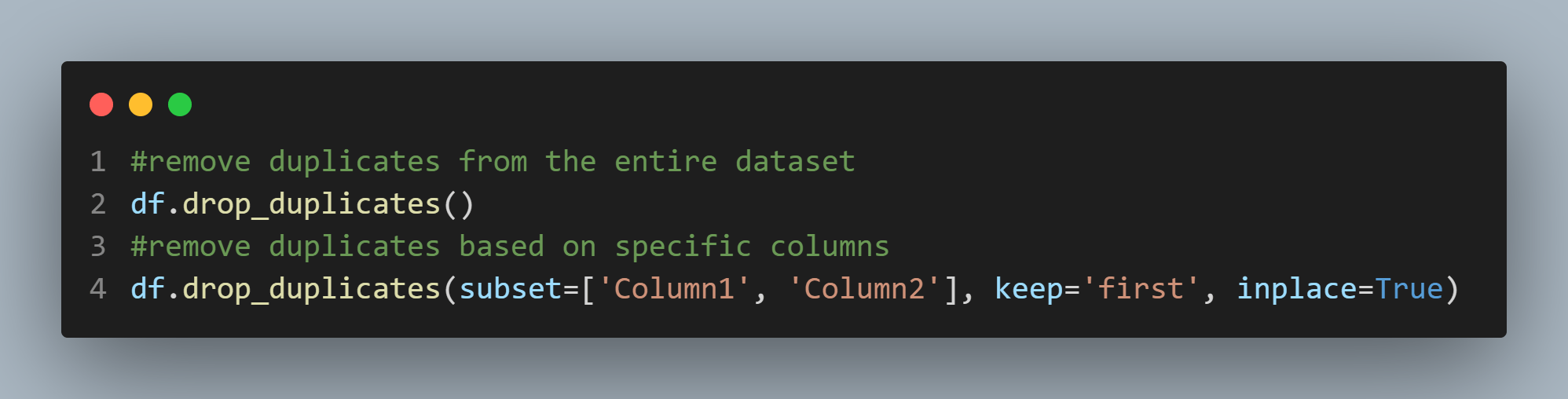
Duplicates can distort analyses. Removing them is an important data-cleaning step. By removing duplicates, analysts can ensure that each data point is unique and representative of the true dataset. This helps in avoiding any biased conclusions or inaccurate insights that may arise from counting the same data multiple times. Moreover, eliminating duplicates improves the overall quality and reliability of the data, making it more suitable for meaningful analysis and decision-making processes.
3. Handling Outliers
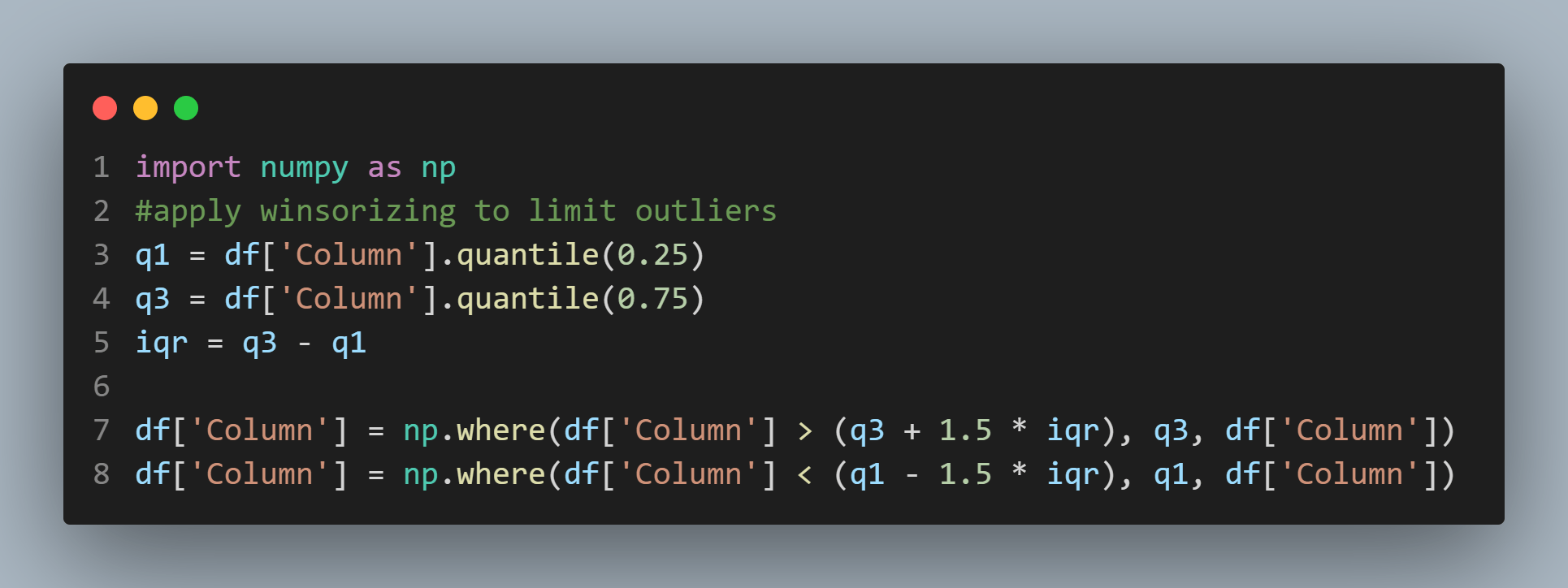
Outliers in statistical analyses can significantly impact the results. Identifying and addressing these outliers is crucial. Graphic methods like box plots or scatterplots can help visualize these differences. Once identified, it’s crucial to determine if they’re due to data entry errors or true deviations from the norm. Addressing outliers may involve removing them or transforming the data to minimize their impact.
4. Data Normalization and Scaling
Scaling features to a similar range prevents one feature from dominating others, especially in machine learning. This ensures no single feature has an unfair advantage, resulting in a more balanced and accurate representation of data. This leads to more reliable predictions or classifications, making scaling features crucial for achieving optimal model performance and avoiding biased results.

5. Handling Categorical Variables
Machine learning algorithms rely on encoding categorical variables, which converts them into numerical representations like integers or binary values. This process aids in understanding and interpreting categorical data, enabling accurate predictions or classifications. Techniques like one-hot encoding or label encoding can be applied depending on the variable’s type and nature. Proper encoding enables the full potential of machine learning algorithms for various domains and applications.
6. Handling Dates and Time
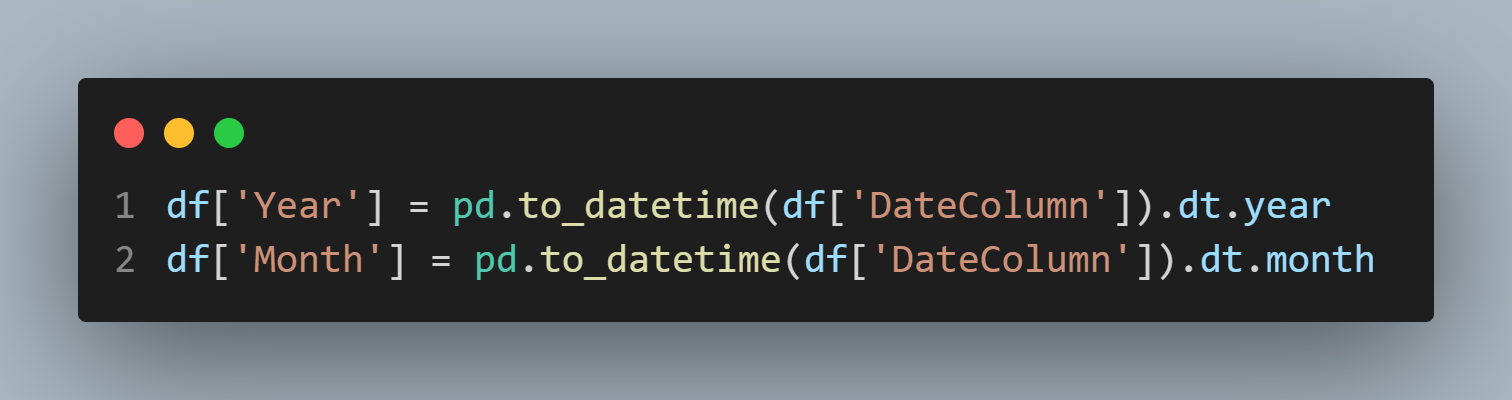
Extracting meaningful information from dates and times can enhance analysis. Analysing dates and times can provide valuable insights for analysts, enabling them to make informed decisions. By understanding patterns and trends, analysts can identify peak buying times and popular engagement times. Combining date and time data with other variables can also create predictive models, allowing for more accurate forecasting of future outcomes. This deeper understanding of phenomena can lead to more informed decision-making.
7. Text Data Preprocessing
For natural language processing tasks, text data needs special treatment. This includes preprocessing steps such as tokenization, stemming, and removing stop words. Tokenization involves splitting the text into individual words or tokens. Stemming helps reduce words to their base form, such as converting “running” to “run”. Removing stop words eliminates common words like “the” and “is” that don’t carry much meaning. These steps ensure that the text data is in a format that can be easily processed and understood by NLP algorithms.

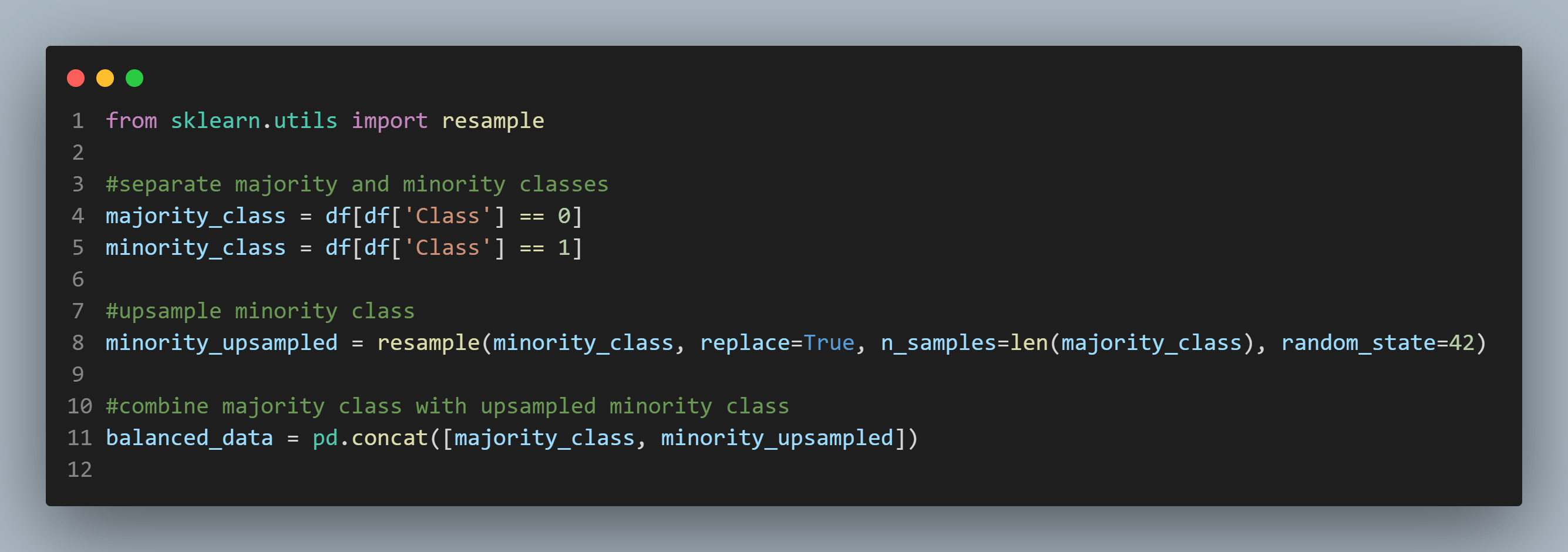
8. Handling Imbalanced Data
In classification tasks, imbalanced classes can lead to biased models. This is because the model will tend to favour the majority class and struggle to accurately predict the minority class. This can be problematic, especially in scenarios where the minority class is of significant interest or importance. To address this issue, various techniques such as oversampling the minority class, undersampling the majority class, or using ensemble methods can be employed to rebalance the classes and improve the model’s performance.
Conclusion
Data cleaning and preprocessing are critical steps in any data analysis or machine learning project. By applying the techniques outlined in this guide, you’ll ensure that your data is in the best possible shape for meaningful analysis. Remember, the effectiveness of your models and insights depends on the quality of your data.
Know more about Data Cleaning. Check our post on Tidy Data.


